




Woran sollte man denken, wenn man Lebenszyklen/Prozesse verknüpfen möchte
Die monolithische Illusion
Die enorme Spezialisierung und Komplexität der Prozesse führt zu einer Intransparenz im gesamten Lebenszyklus und erschwert es, den PLM-Prozess effektiv zu realisieren - d.h. alle Rollen entlang des Lebenszyklus mit den für sie notwendigen Informationen zu versorgen. Schaut man sich die Diskussion in der PLM-Gemeinde an, so kann man erfreulicherweise feststellen, dass die Notwendigkeit der Datenverknüpfung als Mittel zur Operationalisierung von PLM zunehmend erkannt wird, da monolithische Lösungen sich als Illusion erwiesen haben. Die großen Anbieter solcher Lösungen propagieren diese zwar immer noch, aber was sonst können sie anderes tun, als ihr komplettes Portfolio zu verkaufen beziehungsweise von der Autorenlandschaft alle relevanten Standards für Anbindung, Interoperabilität etc. zu erwarten? Die Illusion liegt darin begründet, dass es zu lange dauert und zu kostspielig ist, eine komplexe Datenlandschaft vom Kopf auf die Füße zu stellen. Deshalb braucht man Lösungen, die in der Lage sind, Investitionen in bestehende Autorensysteme zu schützen und gleichzeitig kontrollierte Migrationsprozesse zu ermöglichen, falls Systeme ersetzt oder integriert werden müssen. Wie sehen nun die Vorschläge der PLM-Anbieter an ihre Kunden aus, um Datenverknüpfungsstrategien zu ermöglichen, nachdem sich die Erkenntnisse geändert haben?
Smart PLM Vendors PLM offer Hub Referencing Solutions
Zunächst einmal verkaufen PLM-Anbieter typischerweise ein Wirrwarr an Systemen entlang des Produktlebenszyklus. Aber selbst zusammen machen diese noch keine PLM-Lösung aus. Warum eigentlich? Weil sie nur eine Ansammlung von Systemen sind. Was Sie aber brauchen, ist Geschäftskontext, der durch verknüpfte Daten über die Systeme hinweg materialisiert wird. Insofern ist es ein wenig irreführend, wenn PLM-Anbieter sagen, dass sie PLM-Lösungen verkaufen, um es einmal so auszudrücken. Ignoriert man diese kleine semantische Ungenauigkeit, besteht eine clevere Strategie für einen aufstrebenden PLM-Systemanbieter (wie z.B. Aras) darin, die Vielfalt der Datenlandschaft als Tatsache zu akzeptieren und einen hybriden Ansatz zu verfolgen, der die Daten der anderen Autorensysteme aus der eigenen PDM-Welt heraus verknüpft, d.h. ihr System fungiert als Hub und die anderen sind die Satelliten. Eine solche Verknüpfung muss typischerweise selbst erstellt werden. Da sie Autorensysteme als ihr Kerngeschäft anbieten, kann dies als nahtlose Erweiterung ihres bestehenden Autorensystemportfolios gesehen werden. Für den Kunden bedeutet dies jedoch einen manuellen Aufwand für die Verknüpfung mit Daten anderer Systeme. Das Ergebnis ist die Implementierung eines Graphen innerhalb von Aras (wie es jedes PLM-System hat) zusammen mit der Möglichkeit zur Verknüpfung mit Entitäten außerhalb von Aras. Auf diese Weise wird der Aras-interne Graph zum Hub und die externen Systeme werden zu den Satelliten als untere Enden der Hierarchie. Somit folgt die technische Architektur dem Geschäftsmodell. Es gibt ein Video, das die Demo-Fähigkeiten von Aras Innovator zeigt [1], einschließlich der Verlinkung, die "related part", "outgoing links" und "external links" bietet, um Daten innerhalb und außerhalb des Systems zu verbinden. Letzteres scheint zumindest eine Funktion zu sein, mit der sich Anforderungen über URLs mit Entitäten außerhalb ihrer PDM-Welt verknüpfen lassen. Ich würde dies eher als PLM Hub Referencing Solution bezeichnen (siehe Abbildung 1). Da sie jedoch die geschäftliche Notwendigkeit adressieren, externe Daten zumindest in gewissem Umfang zu verknüpfen, und weil sie diesen technologischen Ansatz mit Geschäftsmodellen wie Offenheit, Subskriptionsmodellen, Pay-per-Use gekoppelt haben, scheinen sie für Kunden attraktiv zu sein. Contact Software verfolgt einen ähnlichen Ansatz in Bezug auf die Verlinkung. Sie bieten Autorenfunktionen wie "Link Graph", um z.B. Anforderungslinks zwischen Entitäten zu modellieren, siehe [5]. Aber auch hier findet die Verlinkung hauptsächlich innerhalb des Systems statt. Wieder andere Anbieter wie openbom verbinden das Geschäftskonzept der "Offenheit" mit einem Narrativ, welches behauptet, dass die Produktstruktur der Kern von PLM ist und es daher ausreicht, die verschiedenen Arten von BOMs (EBOM, MBOM etc.) zu verbinden, um Product Lifecycle Management im eigentlichen Sinne zu realisieren, siehe den Artikel von Oleg Shilovitsky [2]. Innerhalb ihres Systems haben sie zwar eine Darstellung von Linked Data, aber das ist, wie bereits erwähnt, das, was alle PDM-Systeme haben. Die Anbieter entwerfen ihre Systeme so, dass sie für den gesamten Prozess funktionieren, aber das tun sie nie. Das Problem ist die existierende Datenlandschaft, die anderen vorhandenen Systeme (PDMs, Stücklisten, Projektmanagement, Simulation usw.), die von anderen Anbietern geliefert werden. Alle diese Systeme dienen einem bestimmten vertikalen Zweck und sprechen eine andere Sprache. Und selbst wenn es gelingt, Kunden dazu zu bringen, alle offenen Technologien zu kaufen, besteht immer noch eine Ansammlung von Systemen ohne übergreifende Datenkonnektivität. Das ist das gleiche Problem, das die großen Anbieter letztlich haben. Offenheit allein hilft hier kein bisschen, denn es geht nicht um Offenheit, sondern um Datenkonnektivität. Das ist auch der Grund, warum ich Diskussionen über SSOT und SVOT wie von Lionel Grealou in [4] eher als Ablenkungsmanöver betrachte, weil es sich um eine IT-Anbieter-Diskussion über technische Dinge handelt, die durch Vereinbarungen oder Konventionen gelöst werden können. Wie kann man dann Datenvernetzung realisieren?
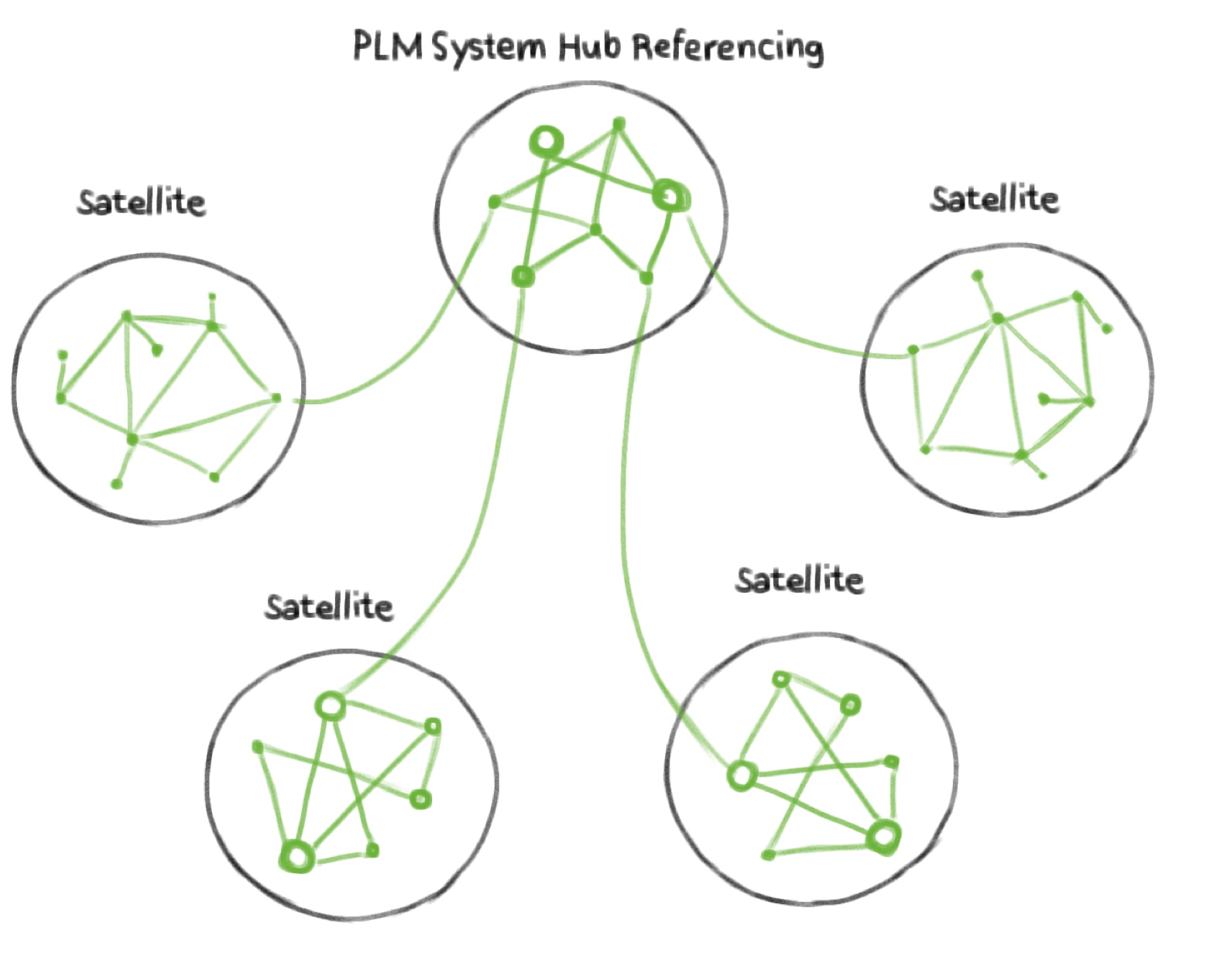
Knowledge Graphen für PLM durch Autorenprozess?
Eine Möglichkeit, die Frage nach der Herstellung von Datenkonnektivität zu beantworten, könnte darin bestehen, die Graphtechnologie als Grundlage von PLM zu verwenden, wie es Ganister tut. Dies könnte ein vielversprechender Ansatz sein, wenn man sich auf einer so genannten "grünen Wiese" befindet, auf der man bei Null anfangen könnte. Aus diesem Grund würde ich Olegs Schlussfolgerung in [2] widersprechen,
...die Graphen in der Fertigung sind riesig, aber die Systeme, die sie ermöglichen, sind noch nicht verfügbar
mit der Behauptung, esgäbe keine technischen Lösungen, um Graphtechnologie im PLM zu etablieren. Die PLM-Anbieter tun sich jedoch schwer, echte Graphtechnologie in ihre Systeme zuintegrieren. Es bräuchte die Fähigkeit zum Entwurf semantischer Datenmodelle, Speicher- und Inferenztechnologie und den ganzen Rest, um skalierbare "Modelle für Wissensgraphen", wie es OlegShilovitsky ausdrückt, bereitzustellen. Das eigentliche Problem mit dem Ansatz von Ganister und ähnlichen Anbieter nist, dass es vermutlich nur einen Bruchteil kleinerer Unternehmen gibt, die mit einem solchen Ansatz auf der grünen Wiese für PLM beginnen könnten. Für diese mag es sehr sinnvoll sein, diesen Weg zu gehen. Für größere Unternehmen mit bestehender Infrastruktur ist eine solche Lösung meiner Meinung nach keine Option, da sie wie die anderen PLM-Anbieter auf das Problem "Verknüpfung des Produktlebenszyklus durch Bearbeitung" stoßen werden.
OSLC als Klebstoff zwischen Autorensystemen
OSLC in Kombination mit RDF-Triple-Stores könnte die Methode der Wahl sein - als das fehlende Glied, um die PLM-Welt mittels einer universellen Modellierungssprache zu verbinden. Damit würde die Notwendigkeit zur Akzeptanz von Vielfalt angesprochen, was positiv ist. Dies wäre jedoch ein Top-Down-Standardisierungsansatz, und wenn man an die vielen Systeme denkt, die man verbinden müsste, ist dies gelinde gesagt nicht der pragmatischste Weg, das Problem zu lösen. Man bräuchte eine universelle Standardsprache, um alle möglichen Beziehungen zwischen Unternehmenssystemen zu beschreiben. Ich würde stark bezweifeln, dass es möglich ist, solch eine Sprache zu entwickeln, um die Gesamtheit des PLM-Wissens (geschweige denn des Unternehmenswissens) auf diese Weise zu modellieren. Aber um des Gedankenexperiments willen lassen Sie uns annehmen, dass es funktionieren würde. Dann werden die Daten in ihrer existierenden Datenlandschaft wahrscheinlich nicht mit dieser "akademischen" Terminologie übereinstimmen. Ich denke, dies würde zu einer nicht enden wollenden Geschichte babylonischer Sprachverwirrung führen. Sie müssten Aufwand betreiben, um Ihre Daten an den auferlegten Standard anzupassen. Das wäre zwar schön für IT-Dienstleister, aber kostspielig für den Kunden, der dafür bezahlen muss. Ein weiterer Nachteil eines solchen Ansatzes ist, dass die Rechenleistung der Graphtechnologie nicht wirklich genutzt werden kann, da es schwierig ist, Inferenzverfahren auf einer Graphdarstellung zu implementieren, die nicht über den gesamten Lebenszyklus, sondern nur von Werkzeug zu Werkzeug gültig ist. Damit ist es nicht ohne weiteres möglich, Inferenzprozesse zu etablieren, die für die Rückverfolgbarkeit notwendig sind - ein wesentliches Merkmal zur Berechnung des Digital Thread und eine Voraussetzung für die Digitalisierung. Der Vorteil wäre allerdings, dass die Modellierungssprache, die die Datenquelle über eine Spaghetti-Architektur verbindet, zumindest standardisiert wäre. Denkt man darüber hinaus an die Rollen entlang des Lebenszyklus und die von ihnen benötigten Informationen, so fällt auf, dass Informationen aus Supply-Chain-Prozessen, After-Sales-, Kunden- und anderen Prozessen auch für PLM-Rollen notwendige Datenquellen sind. Dann müsste man zusätzlich Autorensysteme anbinden, die solche Daten bereitstellen und das Standardmodell mit all seinen Tücken erweitern. Und das würde die Komplexität für die Realisierung der Lösung dramatisch erhöhen, vielleicht ähnlich wie bei monolithischen Lösungen, vielleicht sogar schlimmer.
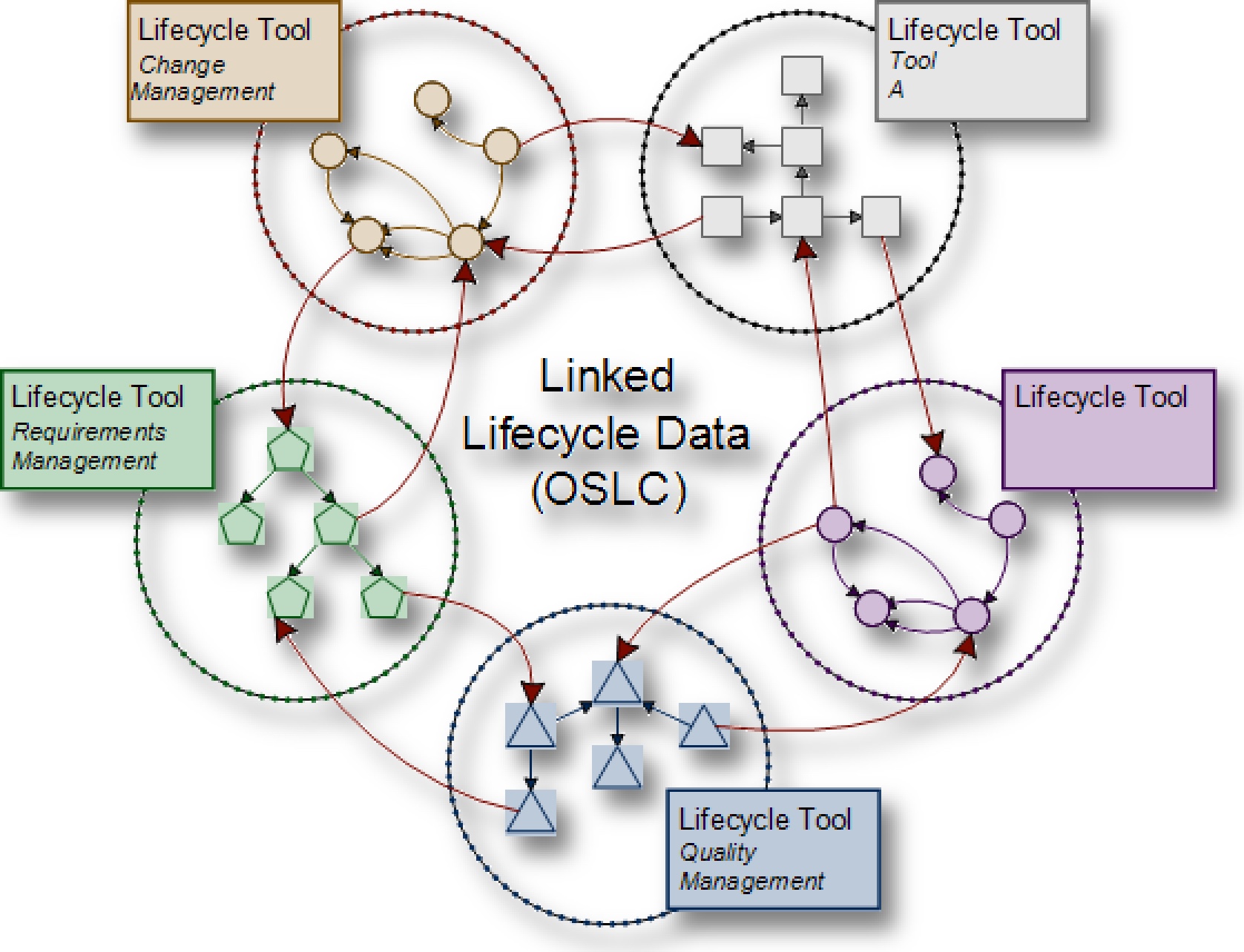
Enterprise Knowledge Graphen
Die von uns favorisierte Lösung ist ein inkrementeller Bottom-up-Ansatz auf Basis von Enterprise Knowledge Graphen (EKGen). Auch sie akzeptieren die Vielfalt als Realität und können als Mittel zur Ausschöpfung von Investitionen in bestehende Datensysteme gesehen werden. Die Idee ist, eine separate, verknüpfte Datenschicht (den Graphen) über den Autorensystemen zu etablieren, die PLM- (und andere) Metadaten verbindet. Dieser Prozess kann weitestgehend automatisiert werden, so dass der manuelle Aufwand minimiert wird. Hinzu kommt, dass es sich hierbei um allgemeine Graphen handelt, die Fähigkeiten wie die Bereitstellung von Inferenzprozessen bieten, welche weit über hierarchische Ansätze hinausgehen - insbesondere über solche, die von einem PDM-Hub in andere Autorensysteme hineinführen. Wesentlich für ein solches Feature ist die vollständige Entkopplung der verknüpften Datenschicht von den Autorensystemen und ein zeitgesteuerter automatischer Aktualisierungsprozess, der laufende Änderungen in den Datensystemen berücksichtigt. Meiner Meinung nach macht es nicht viel Sinn, ein PDM-System (das sind die meisten PLM-Systeme) mit Fähigkeiten zu überfrachten, für die es nicht ausgelegt ist, nämlich die Verknüpfung von Daten über andere Systeme hinweg. Ein Cross-Linking-Ansatz, der auf semantischen Modellen basiert, hat den zusätzlichen Vorteil, dass er beliebige Autorensysteme anbinden kann. Er ist nicht an PLM-Daten gebunden, sondern kann Daten aus verschiedenen Lebenszyklen miteinander verbinden. Deshalb wird der Graph auch Enterprise Knowledge Graph genannt. Nun könnten die Befürworter einer OSLC-Lösung sagen, dass sie einen EKG aufbauen können, indem sie alle lokalen Graphen zu einem EKG verbinden. Aber warum kompliziert, wenn es auch einfach geht? Wenn man die Vielfalt der Datensysteme akzeptiert, dann kann ein inkrementeller Ansatz mit einem erweiterbaren, leicht zu ändernden Datenmodell und einer Analytik, die den Graphen aus den Daten berechnet, in sehr kurzer Zeit bereitgestellt werden. Der EKG kann um die Anwendungsfälle wie Anforderungsverfolgung, Änderungseinflussanalyse, vorausschauende Wartung usw. wachsen, um den PLM-Prozess in einer Art On-Demand abzudecken. In diesem Fall können die Knoten des Graphen und die modellierten Verknüpfungen als De-facto-Standard fungieren, da alle anderen Anwendungen den Graphen nutzen können, wenn der EKG eine offene Zugriffs-API bereitstellt. Gegebenenfalls könnte man sogar RDF oder andere Sprachen als Datenaustauschformat verwenden. Wenn die Automatisierung des Graphenaufbaus mit einem niedrigen Konfigurationsmodus zur Spezifikation der Analytik gekoppelt wird, kann der EKG schnell als Basis für eine Vielzahl von Linked Data-Lösungen etabliert werden. Es hat den zusätzlichen Vorteil, dass es keine spezifische Modellierung und Beschreibung von Datenschnittstellen erfordert und somit keine Belastung für bestehende Systeme und Prozesse darstellt. Es kann mit etablierter Middleware-Technologie einhergehen und On-Premises oder in der Cloud laufen.
Ontology versus Enterprise Knowledge Graph
Was ist der Unterschied zwischen einer Ontologie und einem EKG? Die Wikipedia-Definition von Ontologie verrät: "...Einfacher ausgedrückt, ist eine Ontologie eine Möglichkeit, die Eigenschaften eines Fachgebiets und deren Zusammenhänge darzustellen, indem eine Menge von Konzepten und Kategorien definiert wird, die das Fachgebiet repräsentieren." Mit anderen Worten: Für die konzeptionelle Modellierung von Themen wie Batterie- oder Vergasertechnik oder sogar Unternehmensstrukturen, wie es Oleg Shilovitsky in seinem jüngsten Artikel getan hat, sind Ontologien sehr gute Werkzeuge, da sie tiefes konzeptionelles Wissen über solche vertikalen Domänen darstellen. Im Gegensatz dazu repräsentieren EKGen faktisches Wissen über Lebenszyklen oder Prozesse. Als solche verbinden sie horizontal die verschiedenen Entitäten solcher Prozesse und müssen aufgrund der schieren Menge an Daten aus der existierenden Datenlandschaft automatisiert berechnet werden.
Im Gegensatz dazu ist die Erstellung von Ontologien im Wesentlichen eine intellektuelle Aufgabe und damit ein weitgehend redaktioneller Prozess (allerdings arbeiten wir bei CONWEAVER an Methoden, um auch Vorschläge für Datenmodelle automatisch zu erstellen). Man könnte das Datenmodell, das die Verknüpfungstypen zwischen den Geschäftsobjekten beschreibt, als das konzeptionelle Modell des Wissensgraphen ansehen und dieses Modell als Ontologie bezeichnen, weil die Instanzen aus den abstrakten Konzepten abgeleitet werden. Aber das könnte uns in eine haarspalterische, spitzfindige Diskussion führen, die nicht sehr hilfreich ist. In ähnlicher Weise ist die Diskussion über Standardsprachen wie die Verwendung von RDF, OWL usw. und Triple Stores eine Formsache und lenkt von den wichtigen Dingen ab, z. B. der Fähigkeit, das EKG auf automatisierte Weise von den Autorensystemen nach unten zu generieren. Wenn Sie RDF und all diese Standards verwenden, um Ihre Daten zu repräsentieren und zu speichern, schön und gut. Aber Sie müssen die Verknüpfungen aus den Daten berechnen, bevor Sie sie speichern können, und deshalb müssen Sie das Problem als eine Herausforderung für die Datenanalyse verstehen und nicht so sehr als Problem der Datenrepräsentation. Mit Blick auf unsere Erfahrungen aus realen Kundenprojekten würde ich behaupten, dass die folgenden Funktionen entscheidend sind, wenn Sie die Vielfalt akzeptieren und ein verknüpftes PLM erreichen wollen. Oder allgemeiner, wenn Sie verknüpfte Lebenszyklen (Produktlebenszyklen, Anlagenlebenszyklen, Kundenlebenszyklen usw.) einrichten wollen:
- eine Analytik, die die Erstellung und Aktualisierung des EKGens automatisiert
- eine Repräsentation des EKGen, die von den Autorensystemen selbst entkoppelt ist
- die Fähigkeit, große Knowledge Graphen in der Größenordnung von Terabytes an Eingabedaten zu verarbeiten
- eine Low-Code-Möglichkeit, um Kundenlösungen schnell bereitzustellen
Fazit
Für uns ist die wichtigste geschäftliche Anforderung in Bezug auf unsere Kunden die möglichst weitgehende Wiederverwendung bestehender Ressourcen, und wir beabsichtigen nicht, sie zusätzlich zu belasten, indem wir einen Aufwand für die Bereitstellung standardisierter Sprachen oder den Ersatz von Softwaresystemen verlangen, um starten zu können. Wir schlagen vor, dort anzufangen, wo sie sind, und so viel wie möglich von den bereits vorhandenen Werten zu profitieren, indem wir Analysen und automatische Verknüpfungen nutzen. Ich wiederhole mich, indem ich sage, dass es Systeme gibt, die die semantische Herausforderung von PLM lösen - natürlich nicht die aktuellen PLM-Systeme! Aber ich ermutige jeden, einen Blick auf CONWEAVERs Big-Graph-Low-Code-Plattform Linksphere zu werfen, die bereits von einer Vielzahl von Kunden aus der Automobilindustrie und anderen Bereichen genutzt wird. Aus Sicht von CONWEAVER wäre es sehr sinnvoll, wenn wir eine Zusammenarbeit mit den PLM-Anbietern aufbauen könnten, denn wir sehen uns nicht als technologische Konkurrenten. Manchmal schafft das Teilen mehr für uns alle und hilft dem Kunden.
Für weitere Einblicke sehen Sie auch meine anderen graphbezogenen LinkedIn-Artikel:
- Neue OEM Geschäftsmodelle stellen die Produktentwicklung auf den Kopf
- Betriebssysteme werden Systems Engineering stärken
- Gartner Emerging Technologies: Knowledge Graphen werden zur zentralen Komponente des Data Fabric
- Führt konzeptionelle Unschärfe zu einer Suche nach einem neuen Label für PLM?
- Linked Data Connectivity – Graphen sind die "Crux of the Biscuit"


