




What to consider if you want to establish Connected Lifecycles?
The Monolithic Illusion
The enormous specialization and complexity in the processes leads to a lack of transparency in the entire lifecycle and hinders the PLM process to be effectively realized, that is, to provide all the roles along the lifecycle with the information they need. Looking at the discussion in the PLM community it can fortunately be stated that the need for data linking as a means for operationalization of PLM has been increasingly recognized in favor of monolithic solutions because the latter have been proven to be an illusion, big vendors still promote such solutions but what can they do other than selling their complete portfolio or expect all relevant standards for connection, interoperability etc. from the authoring landscape? The illusion is due to the fact that changing a complex brown field from head to toe takes too long and is too costly. This is why one needs solutions that are able to support leveraging of investments made in existing authoring systems while allowing for controlled migration processes in case systems have to be replaced or integrated. Now that insights have changed, what are the proposals PLM vendors offer their customers to enable data linking strategies?
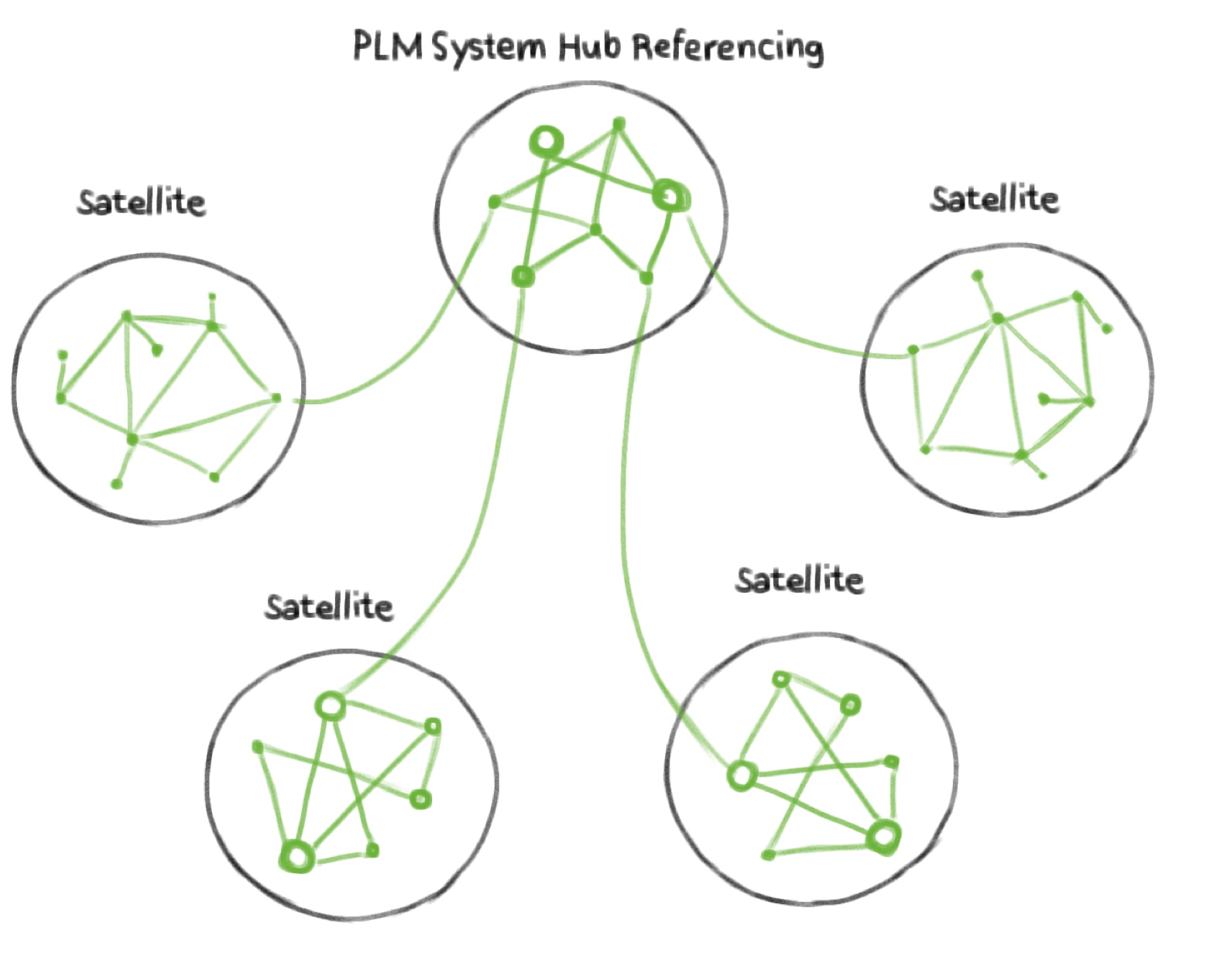
Smart PLM Vendors PLM offer Hub Referencing Solutions
First of all, PLM vendors typically sell a zoo of systems along the product lifecycle. Even together, this does not make them a PLM solution. Why? Because they are just a collection of systems. What you need is business context materialized by means of linked data across the systems. Thus, it is a little misleading if PLM vendors say they sell PLM solutions, to begin with. Ignoring this minor semantic accuracy a clever strategy for an aspiring PLM system vendor (e.g., such as Aras) is to accept diversity of the data landscape as a matter of fact and to follow a hybrid approach which will link up the data of the other authoring systems from their own PDM-world, that is, their system acts as the hub and the others will be the satellites. Such a linking typically needs to be authored. As they offer authoring systems as their core business this can be seen as a seamless extension of their existing editing portfolio. It means, however, for the customer to put manual effort on the linking process to connect to data of other systems. The result will be the implementation of a graph inside Aras (as every PLM system has) together with the ability to link to entities outside Aras. In this way the Aras internal graph becomes the hub and external systems become the the satellites as the lower ends of the hierarchy. Thus, the technical architecture follows the business model. There is a video showing Aras Innovator demo capabilities [1] including linking that offers "related part", "outgoing links" and "external links" to connect data within and outside their system. The latter seems to be at least one feature that can be used to link requirements to entities outside their PDM world via urls. I would call this rather a PLM Hub Referencing Solution (see Figure 1). However, as they address the business need to link up external data at least to some extent and because they have coupled this technological approach with business models such as openness, subscription models, pay per use they appear to be attractive to customers. Contact Software follows a similar approach w.r.t linking. They provide authoring capabilities like "Link Graph" to model, e.g., requirements links between entities, see [5]. But also here the linking takes place mainly inside the system. Still other vendors such as openbom combine the business concept of “openness” with a narrative which claims that the product structure is the core of PLM and thus it is sufficient to connect the different kinds of BOMs (EBOM, MBOM etc.) to realize product lifecycle management in the true sense, see Oleg Shilovitsky's article [2]. Within their system they certainly have a representation of linked data. But this is, as already mentioned, what all PDM systems have. Vendors design their systems to work for the entire process, but they never do. The problem is the brown field, the other systems in place (PDMs, BOMs, Project Management, Simulation, etc.) delivered by other vendors. All these systems serve a specific vertical purpose and speak a different language. And even if you manage to make your customer buy all your open technology you still have a collection of systems and no overarching data connectivity. This is the same problem that big vendors have in the end. Openness alone does not help a bit here because it is not about openness but about data connectivity. This is also the reason why I see discussions about SSOT and SVOT as by Lionel Grealou in [4] rather as distractions because it is a IT vendor's discussion about technicalities can be solved by agreement or convention. How to realize data connectedness then?
Knowledge Graphs for PLM by Authoring?
One way to answer the question about the establishment of data connectivity could be to use graph technology as the foundation of PLM as Ganister do. This might be a promising approach if you are faced with a green field where you could start from scratch. This is why I would contradict Olegs conclusion in [2]
... graphs in manufacturing is huge, but the systems capable of making it happen are not available yet
claiming there are no technical solutions to establish graph technology in PLM. PLM vendors, however, are having are hard time in integrating real graph technology into their systems. It would need the capability for the design of semantic data models, storage and inferencing technology and all the rest of it to provide scalable "models for knowledge graph" as Oleg Shilovitsky puts it. The actual problem with the approach of Ganister and similar vendors is that there is supposedly only a fraction of smaller companies who might start with a green field approach for PLM. For those it might make a lot of sense to take this path. For larger companies with existing infrastructure such a solution is in my opinion no solution because they will run into "linking the product lifecycle by editing" problem like the other PLM vendors.
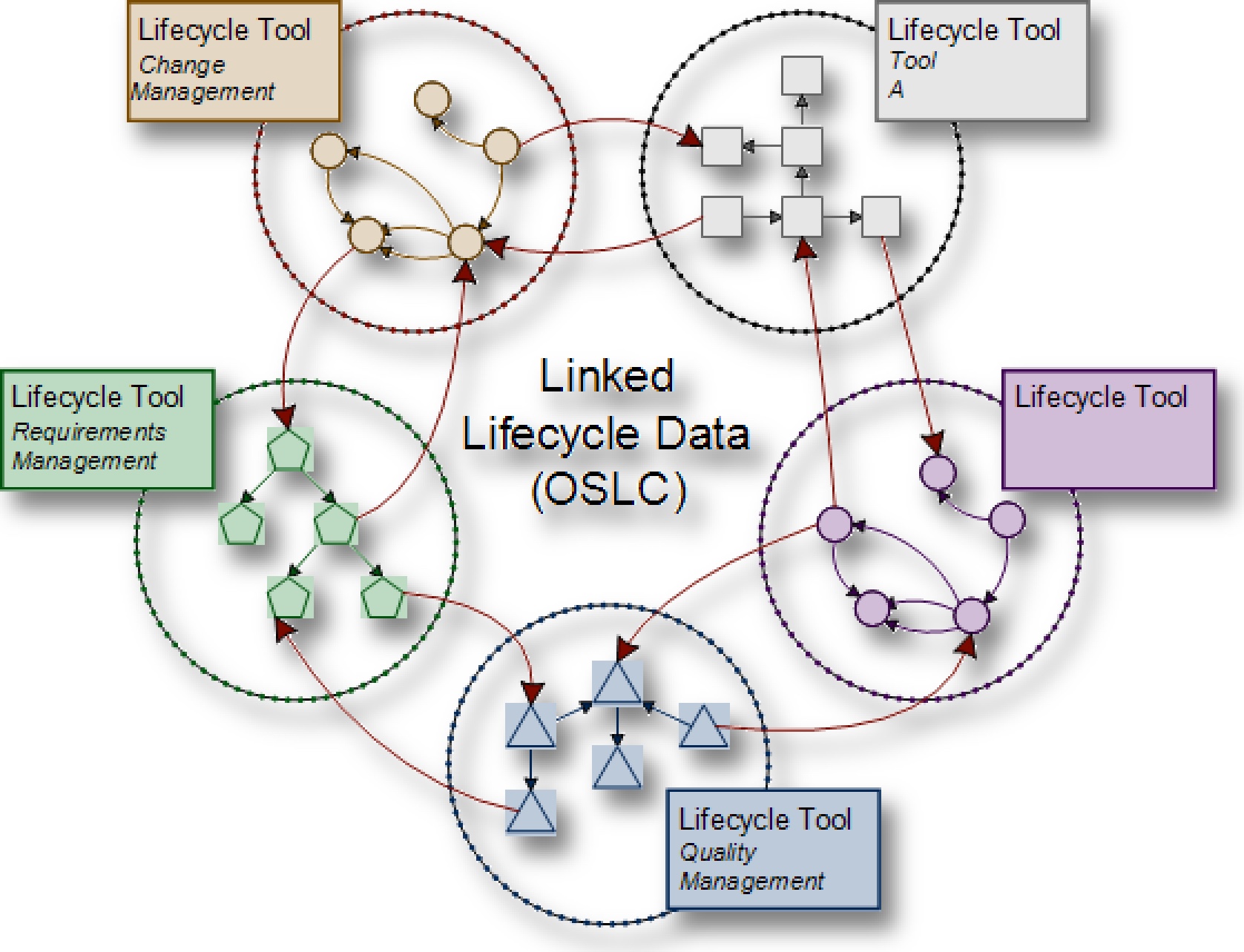
OSLC as the Glue between Authoring Systems
OSLC in combination with RDF triple stores, could be the method of choice, seen as the missing link to connect the PLM world by means of a universal modelling language. This would address the need for acceptance of diversity which is positive. This would, however, be a top-down standardization approach and if one thinks of the many systems one would need to connect this is not the most pragmatic way of solving the problem to say the least. One would need a universal standard language to describe all possible relations between enterprise systems. I would strongly doubt that it is possible to come up with a universal language to model the totality of PLM knowledge only (let alone enterprise knowledge) in this way. But for the sake of thought experiment lets assume it would work. Then the data in your brown field system will likely not match this "academic" terminology. I think this would be going to create a never ending story of Babylonian language confusion. You would need to spend effort in adapting your data to the imposed standard. This would turn out to be nice for IT service companies but costly for the customer who has to pay for it. Another disadvantage of such an approach is that the computational power of graph technology cannot be realized because it is difficult to implement inferencing processes on a graph representation that is not explicit across the overall lifecycle but only from lifecycle tool to lifecycle tool. This means it is not easily possible to establish inferencing processes needed for traceability, an essential feature needed to compute the digital thread and a requirement for digitalization. The advantage would be, however, that the modelling language connecting the data source by means of a spaghetti architecture was at least standardized. On top of that, if one thinks about the roles along the lifecycle and the information they need it occurs that information from supply chain processes, after sales, customer and other processes are required data sources for PLM roles as well. Then you would further need to connect authoring systems providing such data and need to extend your standard model with all its pitfalls. And this would dramatically increase the complexity for the realization of the solution, maybe similar to that of monolithic solutions, maybe even worse.
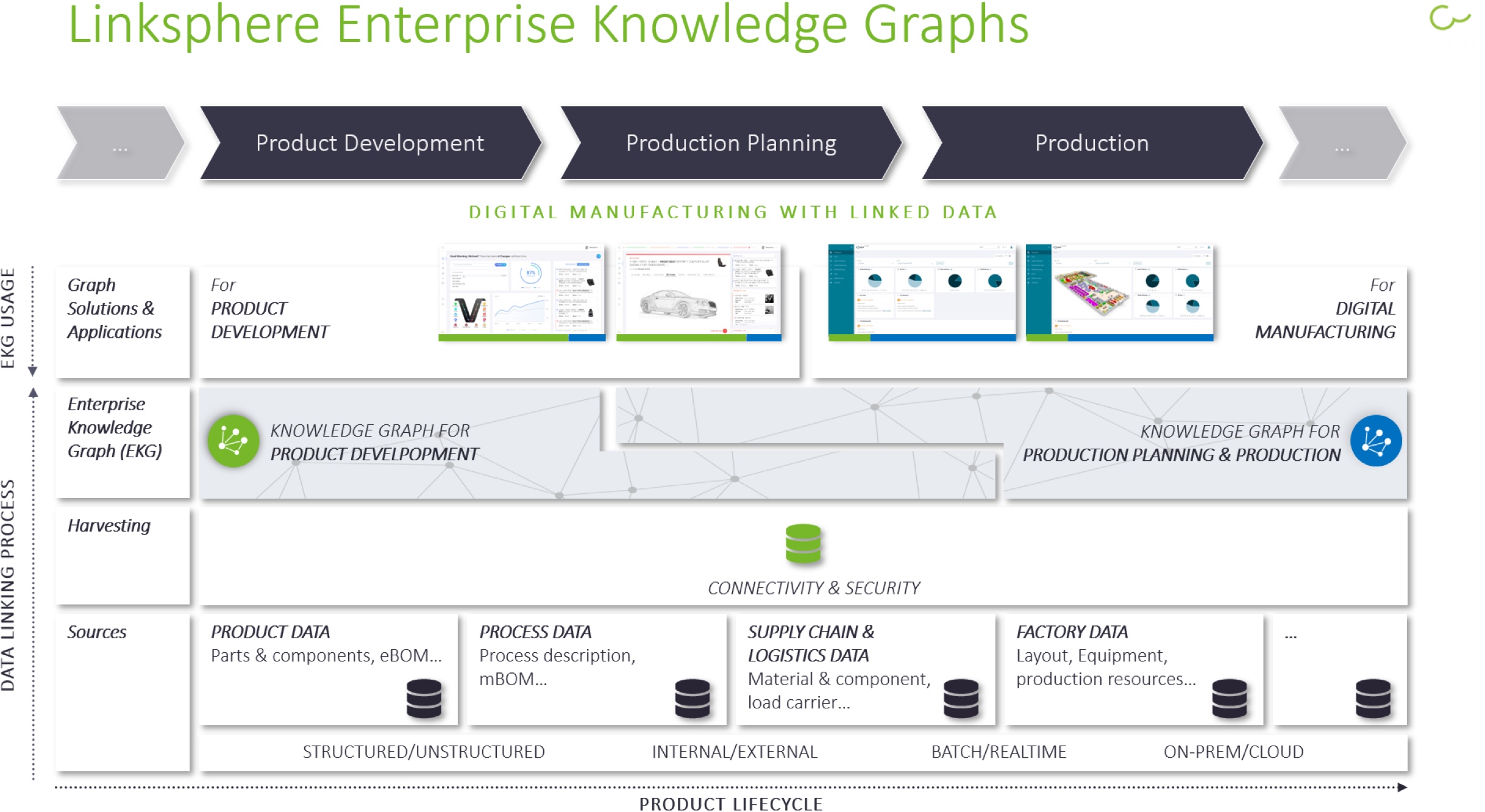
Enterprise Knowledge Graphs
The solution we favor is an incremental bottom-up approach based on Enterprise Knowledge Graphs (EKGs). They too accept diversity as a reality and can be seen as a means to leverage investments made in existing data systems. The idea is to establish a separate linked data layer (the graph) on top of the authoring systems connecting PLM (and other) meta data. This process can to a very large extent be automated so that manual effort will be minimized. Besides the fact that such graphs are general graphs that offer capabilities such as the provision of inferencing processes which go far beyond hierarchic approaches, especially beyond those that link from a PDM hub into other authoring systems. Essential for such a feature is the complete decoupling of the linked data layer from the authoring systems and a scheduled automatic updating process that takes into account ongoing changes in the data systems. In my opinion, it does not make a lot of sense to overload a PDM systems (this is what most PLM systems are) with capabilities for which they are not designed, namely, linking data across other systems. A cross linking approach based on semantic models has the added advantage that it can link up any authoring system. It is not bound to PLM data but can connect data from different lifecycles. That’s why the graph is called Enterprise Knowledge Graph.
Now, proponents of an OSLC solution might say that they could establish a EKG by connecting all local graphs connecting them into a EKG. But why complicated when it can be easy? If you accept variety in data systems then an incremental approach with an extensible, easy to change data model and analytics that compute the graph from the data can be provided in a very short period of time. The EKG can grow by the use cases such as requirements tracking, change impact analysis, predictive maintenance etc., to cover the PLM process in an on-demand fashion. In this case the nodes of the graph and links modelled may act as the de-facto standard because all other applications can make use of the graph if the EKG provides an open access API. If need be you could even exchange data using RDF or other languages as a data exchange format. If the automation of graph construction is coupled with a low configuration mode to specify the analytics then the EKG can be established quickly as a basis for a variety of linked data solutions. It has the additional advantage that it does not require any specific modelling and description of data interfaces, and thus puts no burden on existing systems and processes. It can go along with well-established middleware technology and run on premise or in the cloud.
Ontology versus Enterprise Knowledge Graph
What is the difference between an ontology and an EKG? The Wikipedia definition of ontology reveals “…More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of concepts and categories that represent the subject.” In other words, for the conceptual modelling of subject matters such as battery or carburetor technology or even company structure as Oleg Shilovitsky did in his recent article ontologies are very good tools as they represent deep conceptual knowledge about such vertical domains. In contrast, EKGs represent factual knowledge about lifecycles or processes. As such they horizontally connect the different entities of such processes and are due to the sheer magnitude of brown field data required to be computed in an automated fashion.
In contrast, the creation of ontologies is essentially an intellectual task and thus largely an editorial process (though at conweaver we are working on methods to automatically create even proposals for data models). One could see the data model describing the link types connecting the business objects as the conceptual model of the knowledge graph and might call this model an ontology because the instances are derived from the abstract concepts. But this might lead us into a hairsplitting sophistic discussion which is not very helpful. In a similar way the discussion of standard languages such as the use of RDF, OWL etc. and triple stores is a technicality and diverts the focus from the important things, e.g., the ability to generate the EKG in an automated fashion from the authoring systems down the stream. If you use RDF and all these standards to represent and store your data, fine, but you have to compute the links from the data before you can store them and this is why you have to understand the problem as a data analytics challenge and not so much as data representation problem in the first place. Regarding our experience based on real customer projects I would claim that the following features are crucial if you accept variety and want to achieve a linked PLM, or more generally, if you want to establish connected lifecycles (product life cycles, asset lifecycle, customer lifecycle, etc.):
- analytics that automate the generation and updates of the EKG
- a representation of the EKG which is decoupled from the authoring systems themselves
- the ability to handle large scale knowledge graphs in the order of terabytes of input data
- A low code way to provide customer solutions quickly
Conclusion
For us the most prominent business requirement with regard to our customers is to make as much reuse of existing assets as possible and we do not intend to put additional burden on them by requiring effort to provide standardized languages or replacements of software systems to be able to start. We propose to begin from where they are and leverage as much existing value as possible using analytics and automated linking. I repeat myself by saying there are systems available to solve the semantic challenge of PLM, obvioulsy not current PLM systems but I encourage everyone to have a look at Conweaver's big graph low code platform Linksphere which is already in use by a variety of automotive and other customers. From Conweaver's point of view it would make a lot of sense if we could establish a collaboration with the PLM vendors because we do not see ourselves as technological competitors. Sometimes sharing creates more for all of us and helps the customer.
For more insights see also my other graph related LinkedIn articles:
- New OEMs Business Models Change Product Development from Head to Toe
- Operating Systems will Empower Systems Engineering
- Gartner Emerging Technologies: Knowledge Graphs Become Central Component for Data Fabric
- Does conceptional confusion lead to a search for a new label for PLM?
- Linked Data Connectivity – Graphs are the Crux of the Biscuit



